
Time for a new blog, this time about the impact of network maintenance on VMWare vSAN. This is a situation I also presented at the VMUGNL on June 14th, 2022. At this customer network maintenance was carried out and then VMware vSAN seemed to be not working anymore. All VMs showed the status as “invalid” and believe me, sweat started to poor. Let’s go back in time and find out what happened here.
Table of Contents
The network
Traditionally a network consists of some switches and when a loop was created, often to provide redundant paths, the Spanning-Tree Protocol (STP) took care of that. STP works with a so-called “root bridge” to where all routes are calculated towards, thus eliminating loops. One flavor of the STP is the Rapid Spanning Tree Protocol (RSTP) which was used by this customer. RSTP lowers the needed time for the calculations down to roughly 15 seconds limiting downtime in the network. The original network design is shown in the following network diagram:
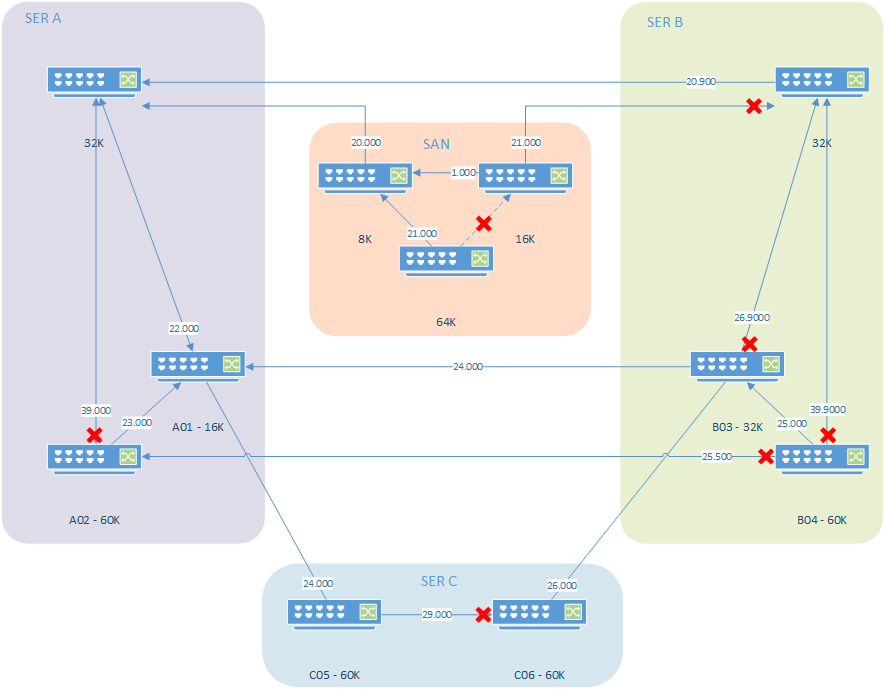
What we see here is that STP eliminated the loops by blocking network traffic on the links shown with a red X. This way the network is loop-free and will keep functioning. During this planned maintenance window the upmost two switches would be replaced with new, quicker, hardware. Also, the old SAN switches (in orange) would be decommissioned. With the decommissioning of the SAN switches the STP root bridge would change from a current SAN switch to the new upper switch in SER A. The updating of the root bridge means that calculations need to be performed to find the new root bridge and these calculations will block all network traffic on connected ports for roughly 15 seconds. Those 15 seconds have a big impact on connected services.
VMware vSAN
VMware vSAN is VMware’s solution to provide storage to VMs that is distributed over the ESXi nodes. I found that the VMware Docs page for vSAN explained it quite well:
VMware vSAN uses a software-defined approach that creates shared storage for virtual machines. It virtualizes the local physical storage resources of ESXi hosts and turns them into pools of storage that can be divided and assigned to virtual machines and applications according to their quality-of-service requirements. vSAN is implemented directly in the ESXi hypervisor.VMware Docs
I’m not going to deep dive into how vSAN works and how to configure it but what is important to know is that vSAN provides the possibility for the VM and the hard disk to be active on separate ESXi nodes. So the VM can have its CPU and memory resources on ESXi-04 while the disk of the VM is active on ESXi-01, ESXi02, and ESXi-03. This means that there is a huge dependency on the network since ESXi-04 must be able to reach the other ESXi nodes to process disk I/O otherwise the VM will crash.
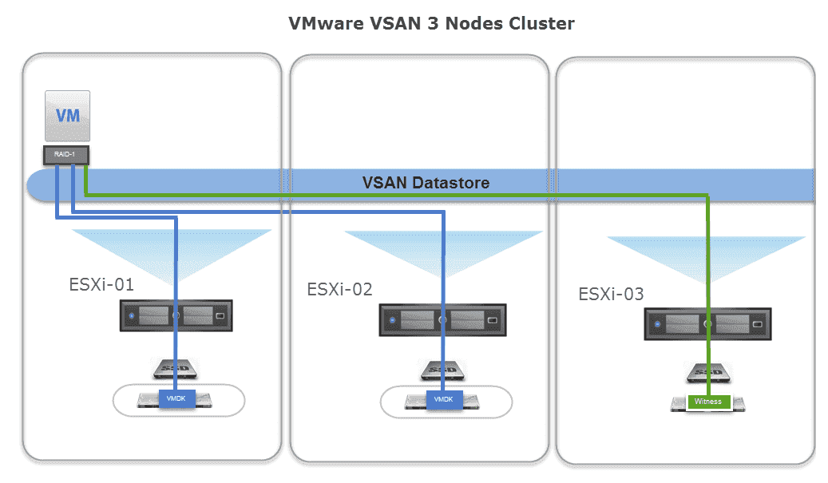
In conclusion
In short, that is the most important part of this blog, VMware vSAN relies heavily on the network. STP root bridge calculation block network traffic on the ports for 15 seconds meaning that no it’s probable that most VMs are no longer able to access their hard disk. So it’s important to keep in mind that, when using any technology like the STP, network maintenance will also have a huge impact on vSAN. I’ll continue this blog with some steps taken during this specific maintenance window since there was a slightly bigger issue after everything was finished. I’d like to take you along some troubleshooting steps performed.
The situation
As written in “the network” part of this blog, the current root bridge of this network was to be removed, and a new root bridge was to be configured during this planned maintenance. This meant that all traffic, on all connected network ports throughout the spanning-tree, will be blocked for about 15 seconds. This includes all ports used by the ESXi servers for VMware vSAN. In the conversations leading up to the maintenance, this became known as it had a big impact on the required size of the maintenance window since now vSAN will need completely shutdown to prevent any data loss.
Shutdown vSAN
The shutdown was planned with the help of VMware Docs. It’s a quite elaborate doc and VMware is actively working to improve to process, since version vSAN 7.0 Update 3 there is a “shutdown cluster” wizard added to the UI that helps to gracefully shutdown a vSAN cluster for maintenance. Since, at the time, we had U1 in place, all steps were done manually but all went well 😊. Steps that were needed (before 7.0 U3) come down to this:
- Power off all Virtual Machines (VMs) running in the vSAN cluster
- Turn off High Availability (HA) (this is to remove the vCLS VMs)
- Wait till all vSAN objects are finished syncing.
- Power off the vCenter server VM and write down the ESXi host it was running on.
- Prepare the cluster for shutdown from the CLI with the following command `
esxcli system maintenanceMode set -e true -m noAction` - Power down the VMware nodes

Power on vSAN
In VMware environments, the vCenter server is rather important and is, therefore, one of the first, if not the first, VM to be powered on again. After the maintenance to the network was finished the ESXi nodes were booted again so all VMs should be accessible and the VMs ready to boot. We logged in to the ESXi node that we know had the vCenter server VM and start searching for the VM but sadly all the VMs show the status “Invalid” which lead to a big shock, did we just lose all our VMs? A quick check on the CLI shows that the vSAN health is shown as “red” just as the object health (well luckily there are still objects).
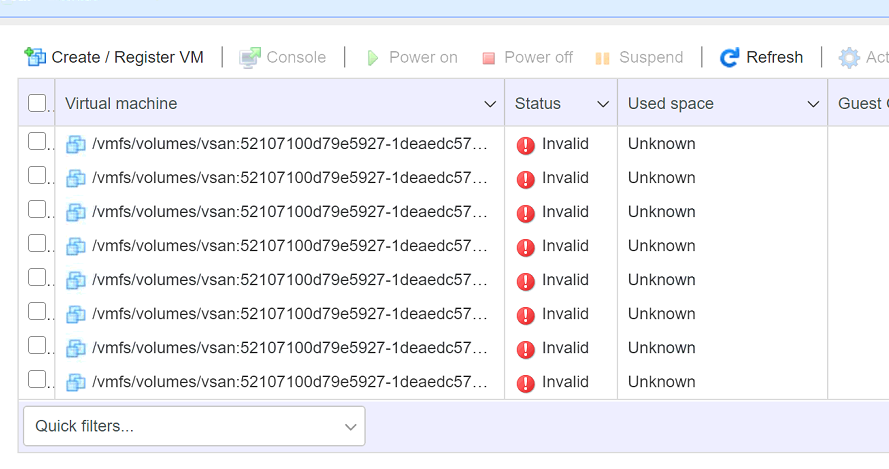
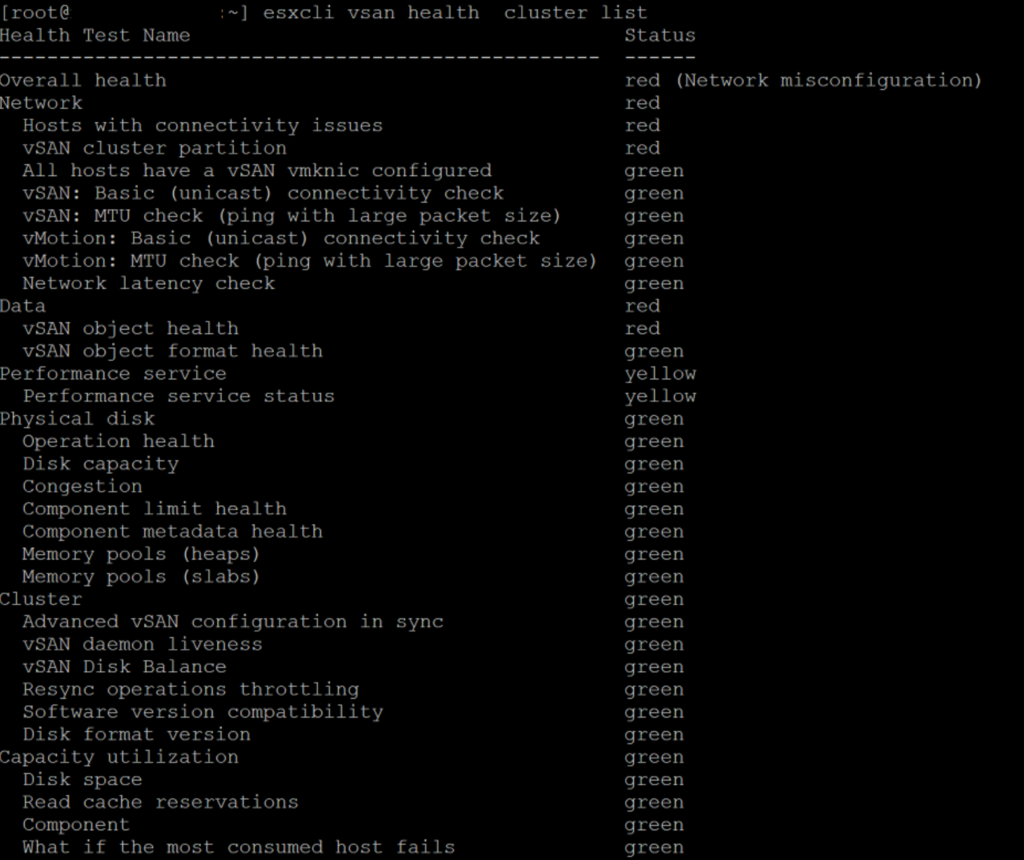
Troubleshooting steps
One of the first thing I decided to check is the vSAN health via the CLI command `esxcli vsan debug object health summary get`. This command shows the availability of the objects known to VMware vSAN. Equal to the vSphere host client, it did not give a good image as it showed 563 objects as “inaccessible”.
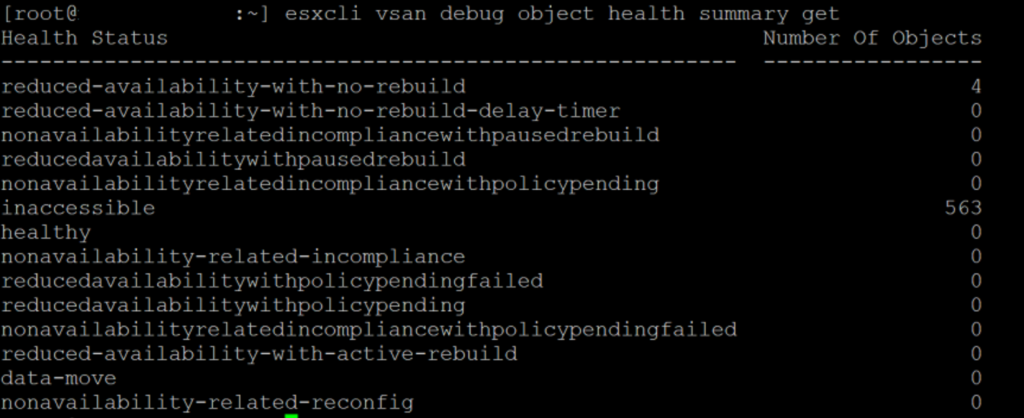
I tried convincing VMware to reload the VMs from the CLI, but sadly this also didn’t help anything. In the end the VM status stayed the same. Also restarting an vSAN node didn’t help with chancing the status of the VMs although the boot took some time to recover vSAN services.
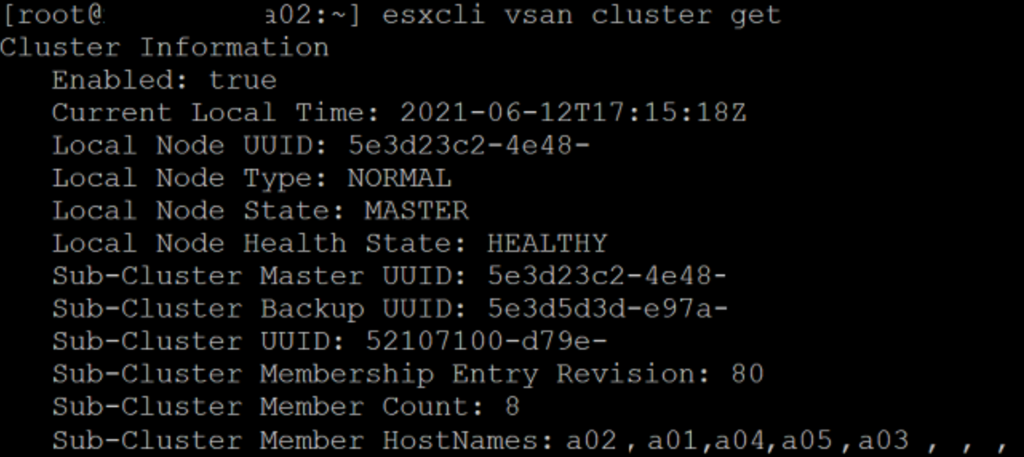
With that information in mind I started looking deeper into the vSAN environment, maybe check if all nodes are participating in the vSAN datastore? With the command `esxcli vsan cluster get` it’s possible to see cluster information but most importantly, the hostnames of the nodes providing services to vSAN. With this output it became clear that only one location seem to participating (only A servers show up), and the issue might still be in the network.
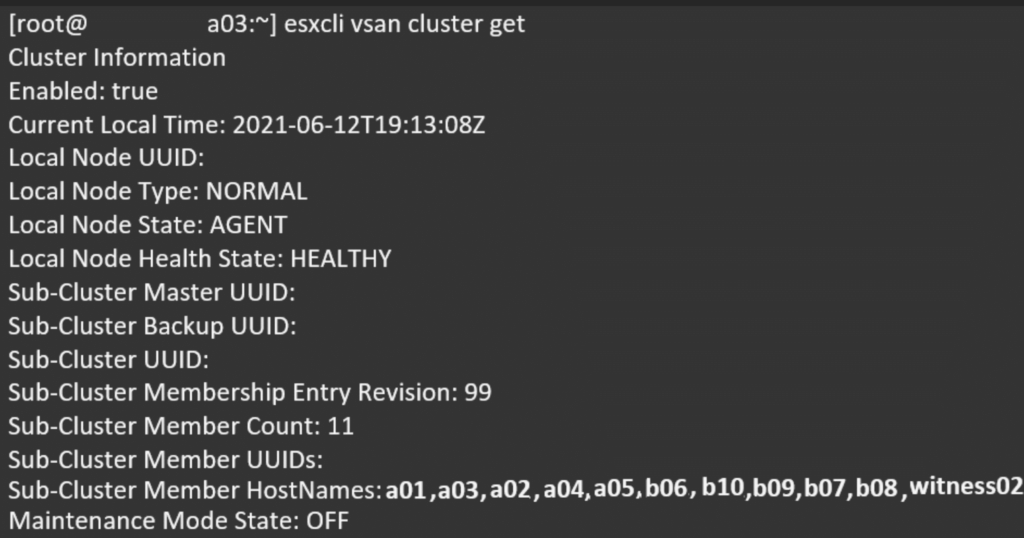
It turned out that the spanning-tree was not configured right, this completely isolated the three locations (A, B, and witness) preventing vSAN to get to the required minimum of two locations to be able to access the VMs. After restoring the spanning-tree to the designed state the nodes were able to communicate and now the cluster did list all the nodes as expected. VMware vSAN then automatically started to repair the VM files.
Key take aways
So long story short, here’s a list of things to keep in mind while troubleshooting VMware vSAN.
- As long as you are not clearing/wiping/repartitioning vSAN disk(s) your data is safe!
- Make sure all participating nodes can communicate
- Check with `
vmkping` if the nodes can ping each other - Check with `
esxcli vsan debug object health summary get`
- Check with `
- Make sure all participating nodes can reach the vSAN witness
- Check if `
vmkping` is possible from the nodes to the vSAN witness - Check if vSAN witness traffic is using the right vmkport or update on each node with
esxcli vsan network ip add -i vmk0 -T witness
- Check if `
- Make sure any intermediate firewall allows the vSAN communication
- Check communication to and from the nodes to the vSAN witness using the VMware Ports vSAN website
- If needed, reboot a vSAN node and keep an eye on the DCUI for status updates
- When you have production support at VMware, don’t hesitate to create an incident with the right severity
But most of all, make sure you create an emergency plan on how to shutdown/power on the vSAN environment!
Closing thoughts
Thanks for reading! Hopefully, you found it interesting, and maybe you’ve even learned something new! Want to get a notification when I post a new blog? Leave your email address down below to subscribe! Any questions or just want to leave a remark? Please do so, I’m always curious to read what you think of my content. Enjoy your day!
